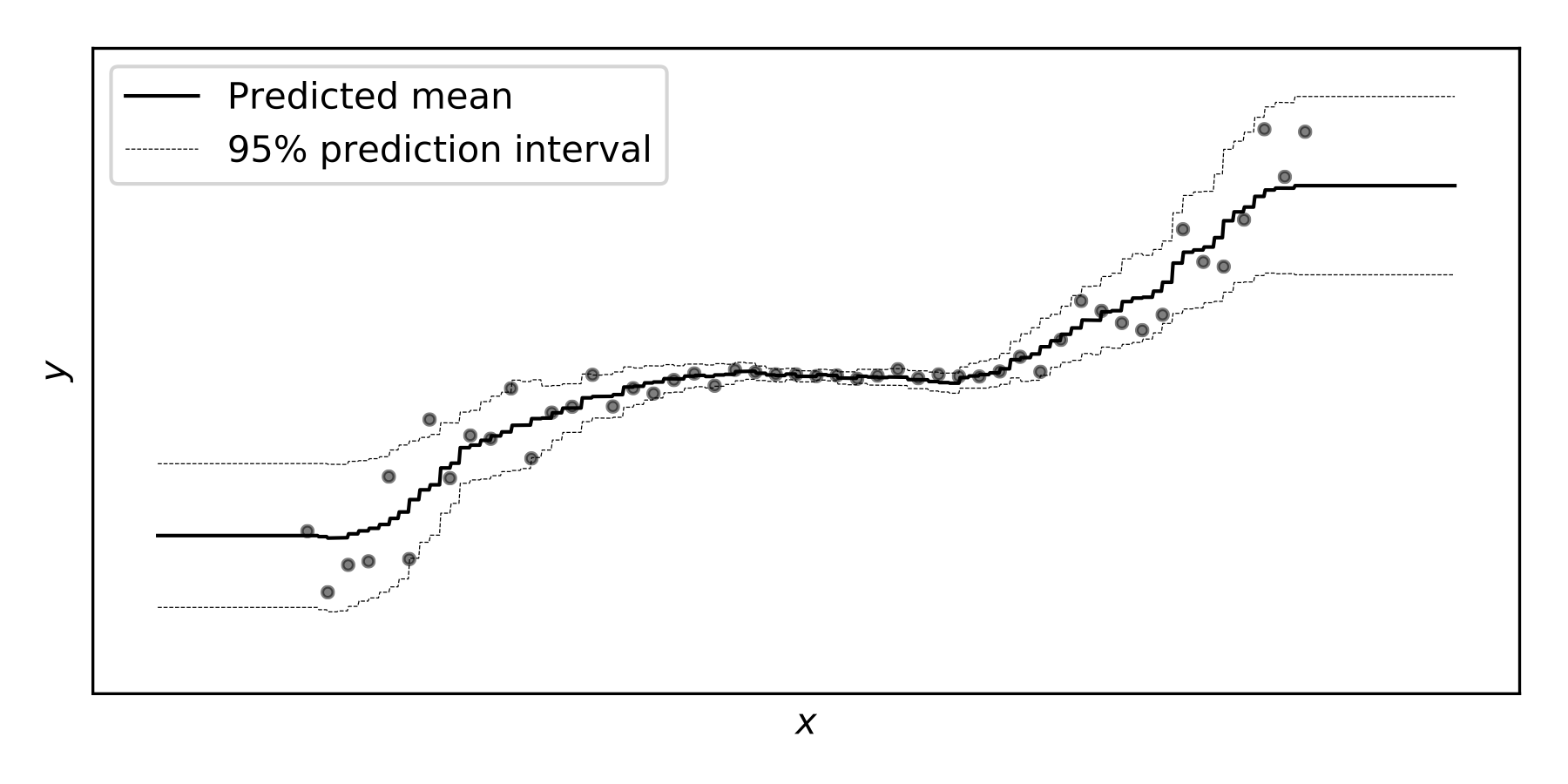
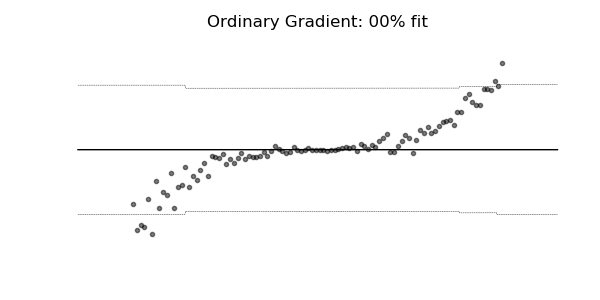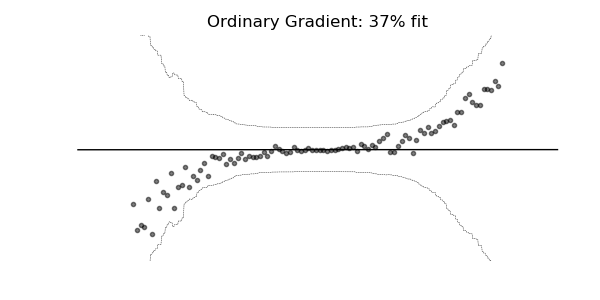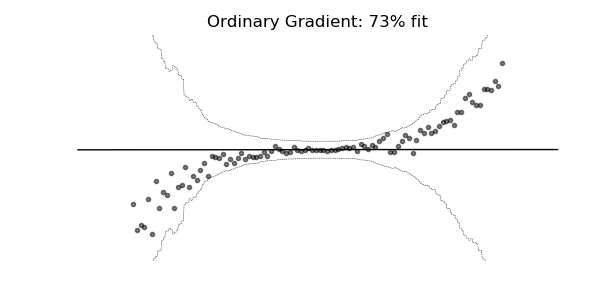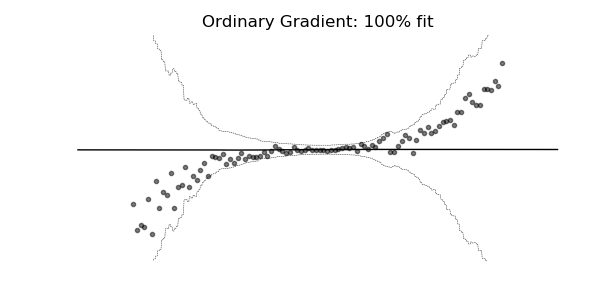
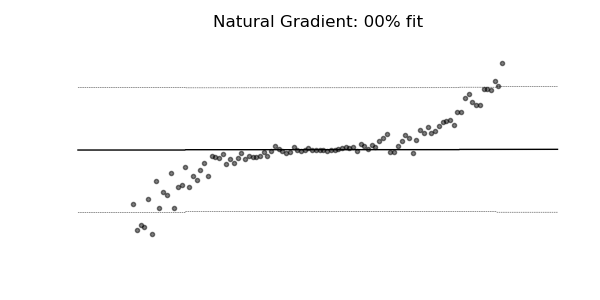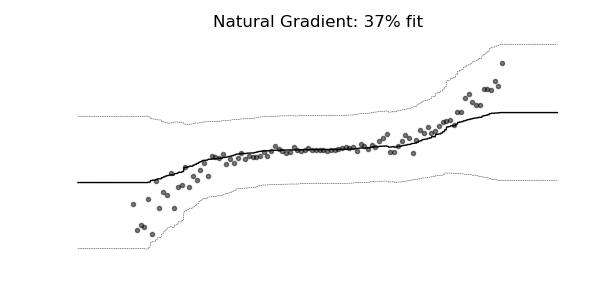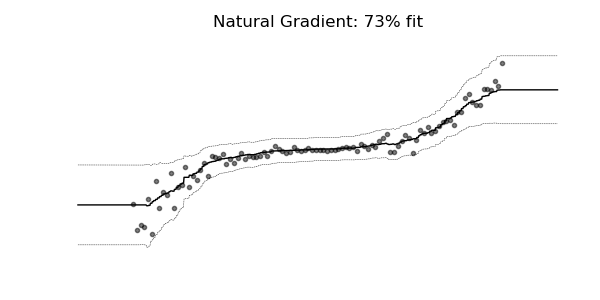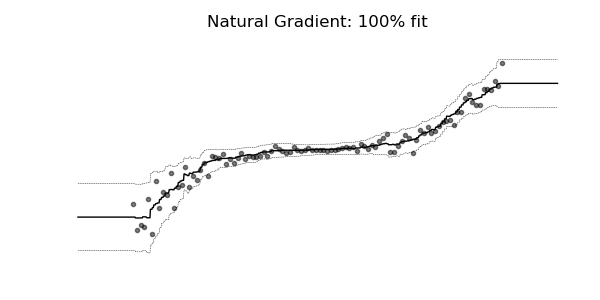
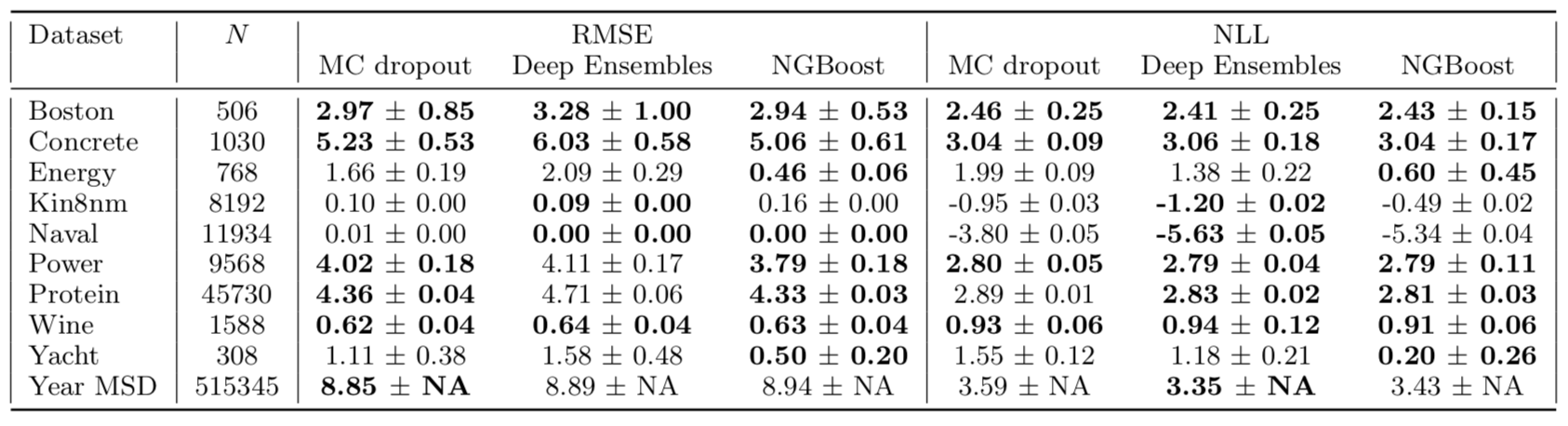
Predictive Uncertainty Estimation in the real world.
Estimating the uncertainty in the predictions of a machine learning model is crucial for production deployments in the real world. Not only do we want our models to make accurate predictions, but we also want a correct estimate of uncertainty along with each prediction. When model predictions are part of an automated decision-making workflow or production line, predictive uncertainty estimates are important for determining manual fallback alternatives or for human inspection and intervenion.
Probabilistic prediction (or probabilistic forecasting), which is the approach where the model outputs a full probability distribution over the entire outcome space, is a natural way to quantify those uncertainties.
Compare the point predictions vs probabilistic predictions in the following examples.
| Question | Point Prediction (No uncertainty estimate) | Probabilistic Prediction (Uncertainty is implicit) |
|---|---|---|
| What will be the temperature at noon tomorrow? | 73.4 Fahrenheit | 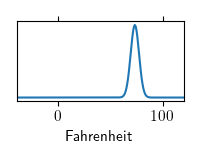 |
| How long will this patient live? | 11.3 months | 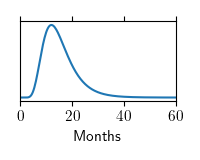 |