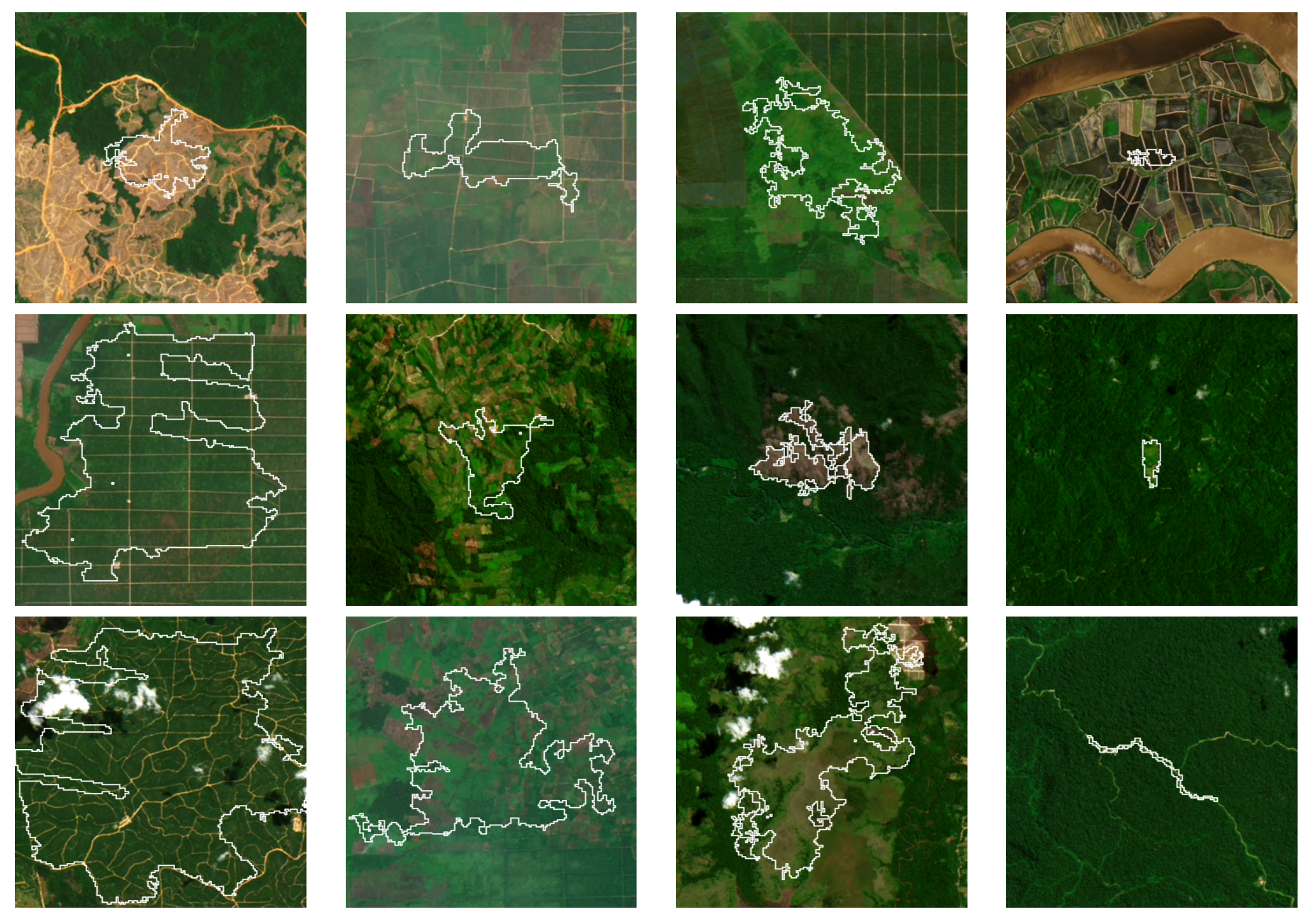
We developed a deep learning model called ForestNet to classify the drivers of deforestation using satellite imagery.
Characterizing the processes leading to deforestation is critical to the development and implementation of targeted forest conservation and management policies. Methods to automate forest loss driver classification enable spatially-broad and temporally-dense driver attribution with significant implications on forest conservation policies.
Read The Paper (Irvin & Sheng et al.)