CheXpert models generalize to data from an external institution
We evaluated the performance of the top CheXpert models on a dataset from an external institution (NIH). Chest x-ray algorithms developed from data from one institution have not shown sustained performance when externally validated on data from a different unrelated institution. This is critical for safe deployment of these algorithms across healthcare systems.
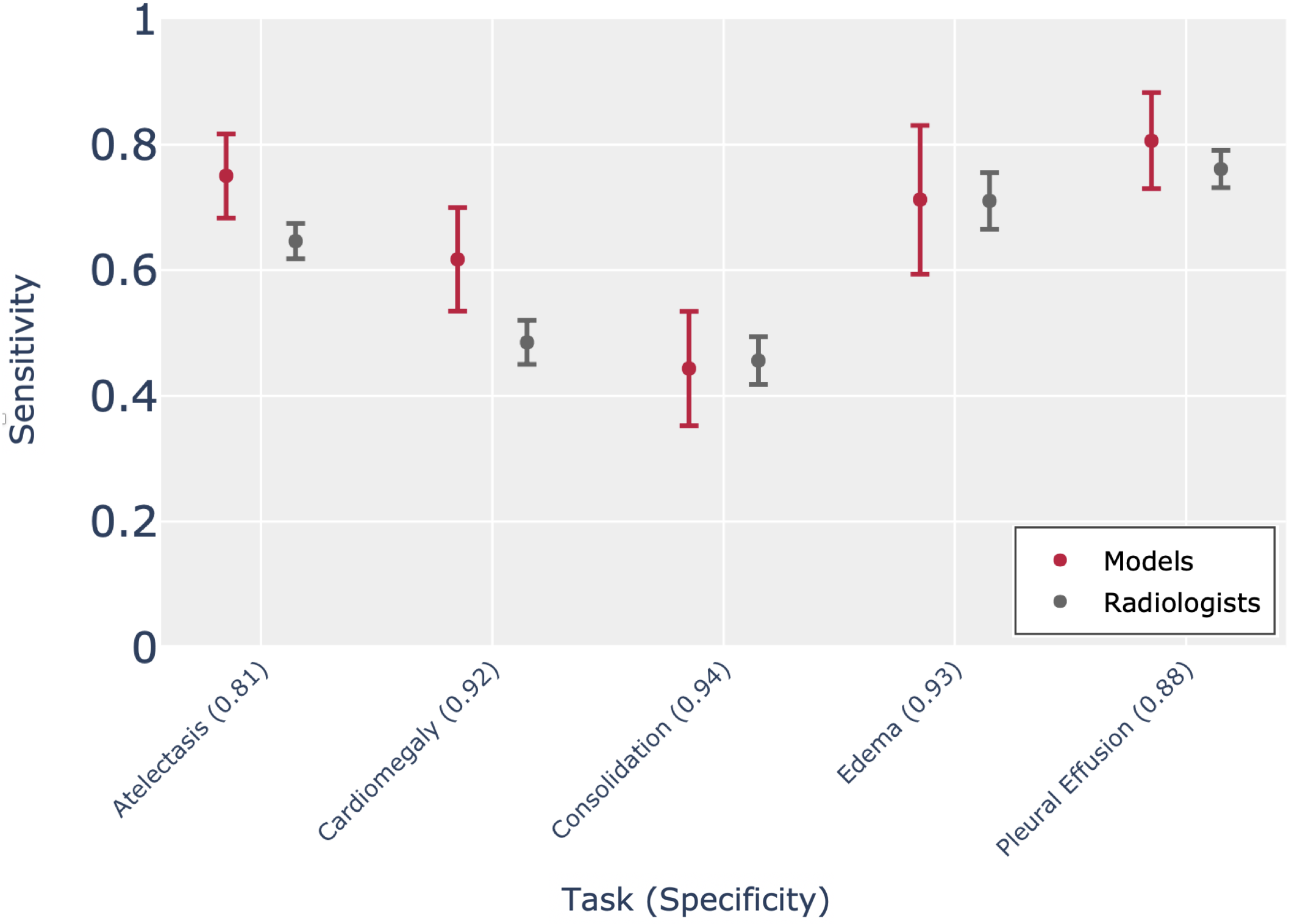
The models achieved an average performance of 0.897 AUC across the 5 CheXpert competition tasks on the test set from the external institution. On Atelectasis, Cardiomegaly, Edema, and Pleural Effusion, the mean sensitivities of the models of 0.750, 0.617, 0.712, and 0.806 respectively, are higher than the mean radiologist sensitivities of 0.646, 0.485, 0.710, and 0.761 (at the mean radiologist specificities of 0.806, 0.924, 0.925, and 0.883 respectively). On Consolidation, the mean sensitivity of the models of 0.443 is lower than the mean radiologist sensitivity of 0.456 (at the mean radiologist specificity of 0.935).
Partner with us