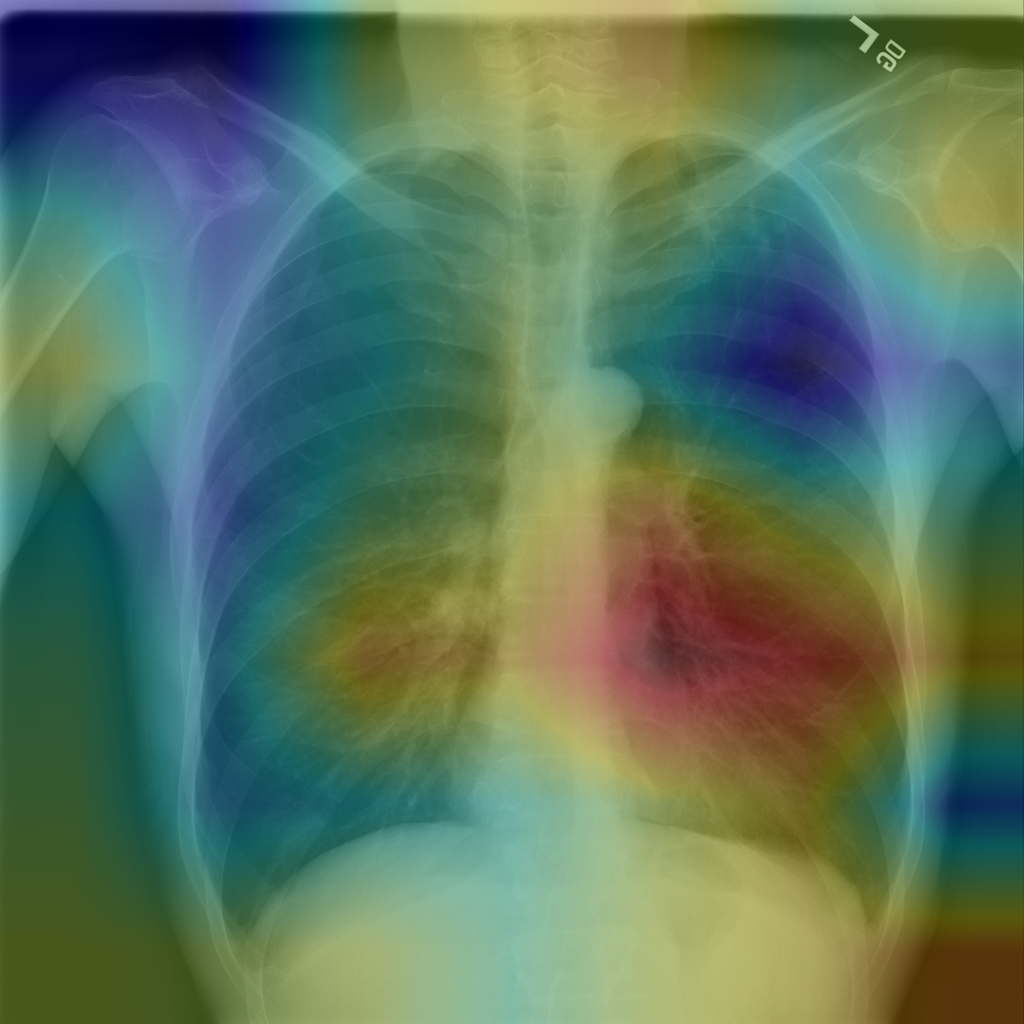
We train on ChestX-ray14, the largest publicly available chest X- ray dataset.
The dataset, released by the NIH, contains 112,120 frontal-view X-ray images of 30,805 unique patients, annotated with up to 14 different thoracic pathology labels using NLP methods on radiology reports. We label images that have pneumonia as one of the annotated pathologies as positive examples and label all other images as negative examples for the pneumonia detection task.
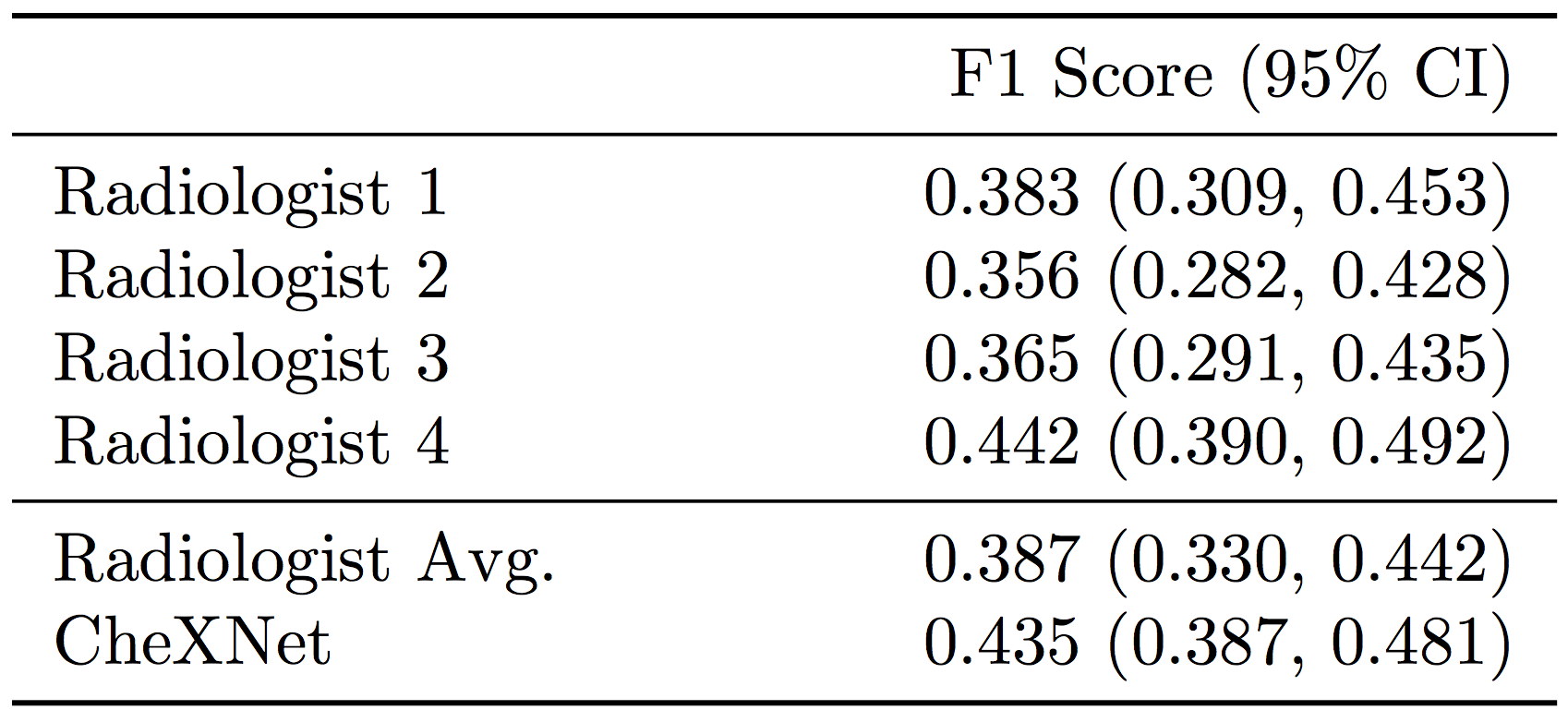
We collected a test set of 420 frontal chest X-rays. Annotations were obtained independently from four practicing radiologists at Stanford University, who were asked to label all 14 pathologies. We then evaluate the performance of an individual radiologist by using the majority vote of the other 3 radiologists as ground truth. Similarly, we evaluate CheXNet using the majority vote of 3 of 4 radiologists, repeated four times to cover all groups of 3.